
Project5: Fun With Diffusion Models!
Part A: The Power of Diffusion Models!
Part 0: Setup
In this part, I use DeepFloyd IF diffusion model. I play around with the three given prompts and I try 2 different num_inference_steps
The random seed I use throughout Part A is 180.
num_inference_steps = 20
an oil painting of a snowy mountain village

a man wearing a hat

a rocket ship

num_inference_steps = 50



From my observation, I personally feel that the first one does not reflect the requirements of oil painting very well, and the result is more like the style of 2D animation.
The second picture does generate an image of a man wearing a hat, but the photo is in black and white. I guess this image is more retro and old-fashioned, so most of the images in the dataset are in black and white.
The third image does not specify the style, but the generated image is in an animation style, probably because descriptions like rocket ship appear more often in children's style images.
Part 1: Sampling Loops
1.1 Implementing the Forward Process
Based on the equation:
the noise follows the Gaussian distribution.

original

Noise Level = 250

Noise Level = 500

Noise Level = 750
1.2 Classical Denoising
I first use
Gaussian blur filtering to try to remove the noise.
The results are not satifying enough.

Noise Level = 250

Noise Level = 500

Noise Level = 750
1.3 One-Step Denoising
Therefore, I use UNet to directly estimate the noise and remove the noise from the noisy image to obtain an estimate of the original image.
original

Noise Level = 250

Noise Level = 500

Noise Level = 750
The method works quite well when Noise Level is low, but when the noise Level becomes higher, it’s still not good enough.
1.4 Iterative Denoising
Using Iterative Denoising based on the equation and Using i_start = 10:

690

540

390

240

90

final
original
one-step
gaussian
The denoise result is much better than the other 2 methods.
1.5 Diffusion Model Sampling
I passed in random noise and used the iterative_denoise to denoise pure noise.
• Show 5 sampled images.





1.6 Classifier-Free Guidance (CFG)
using the Classifier-Free Guidance, we use "a high quality photo" prompt to improve generation.





The ouputs obviously have better quality.
1.7 Image-to-image Translation
In this section, we add noise the the original image, and then we denoise them, to get a higher diversity.
i_start:
1

3

5

7

10

20

original














1.7.1 Editing Hand-Drawn and Web Images
Also, I playe with several nonrealistic images, the avocado is given, the lion was downloaded from the internet and the rest two are hand-drawn images.



























1.7.2 Inpainting
We can implement inpainting of images using similar approaches.
original

mask

to replace

result





The mushroom soup in Mario Restaurant, the model is replaced with an object like a sprite egg




A girl stands in the dark, and the model replaces the girl with someone else. However, due to the large number of cutouts, the photo is a little inconsistent, but I think the model has successfully connected the colors at the bottom of the photo. Without special training, I think this result is pretty good
1.7.3 Text-Conditional Image-to-image Translation
Here, I use prompt to guide the generation procedure.
i_start=
1

3

5

7

10

20

original

this part I use the prompt of a lithograph of waterfalls
and the original image is the Yosemite Half Dome mountain














I use the prompt of an oil painting of a snowy mountain village, the roofs are covered with snow.
the original image is the overlook of Universal Studio.
1.8 Visual Anagrams
In this section, I created pictures which look different when flipped upside down.
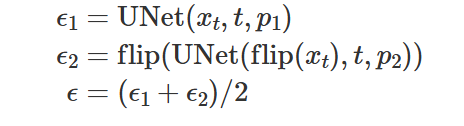

an oil painting of people around a campfire
a lithograph of waterfalls

An Oil Painting of an Old Man

a lithograph of a skull

an oil painting of a snowy mountain village
1.9 Hybrid Images

an oil painting of people around a campfire
In this section, I created pictures which look different when seen from near and far.
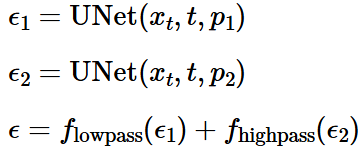

a waterfall
a skull

an oil painting of a snowy mountain village
An Oil Painting of an Old Man

a man wearing a hat
An Oil Painting of People around a Campfire
Part B: Diffusion Models from Scratch!
The second part, we implemented the Diffusion Models from scratch using torch and MNIST dataset.
Deliverable 1 Implementing the Unet & Training a Denoiser
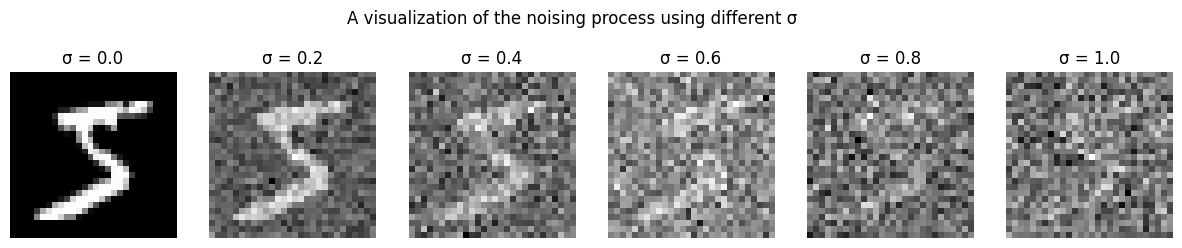
- A visualization of the noising process using σ=[0.0,0.2,0.4,0.5,0.6,0.8,1.0]
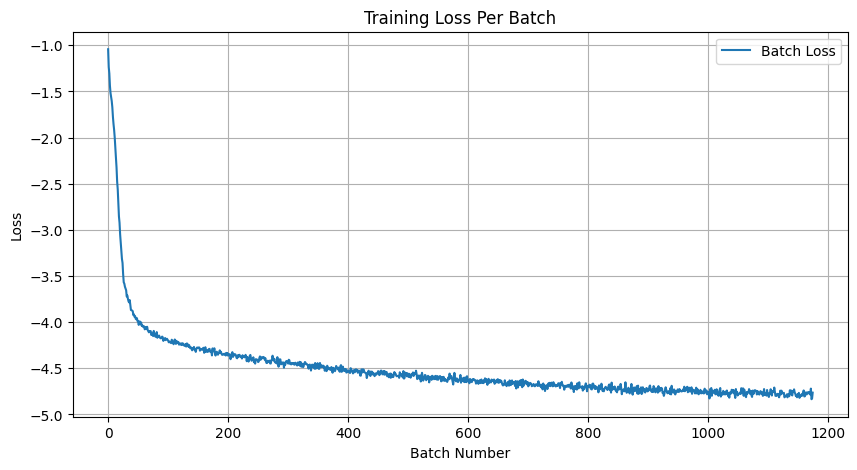
- A training loss curve plot every few iterations during the whole training process
- Sample results on the test set after the first and the 5-th epoch.
after the first epoch

after the 5-th epoch

- Sample results on the test set with out-of-distribution noise levels after the model is trained. Keep the same image and vary σ=[0.0,0.2,0.4,0.5,0.6,0.8,1.0]

Deliverable 2 Time Conditioning to UNet
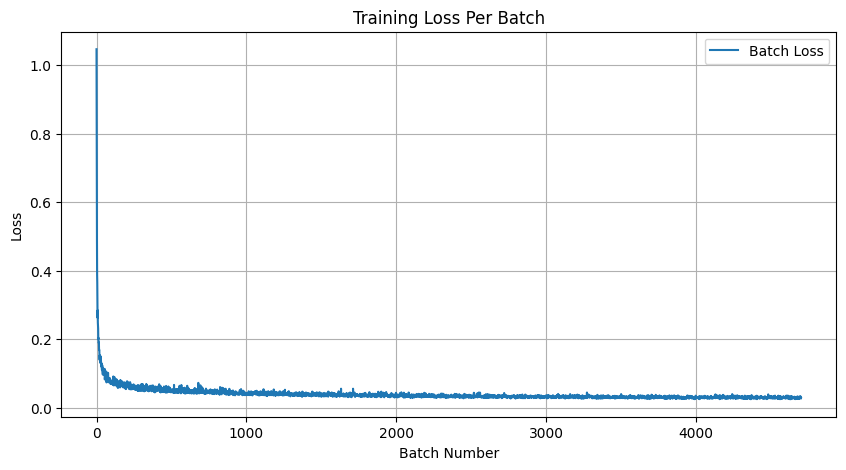
- A training loss curve plot for the time-conditioned UNet over the whole training process.
- Sampling results for the time-conditioned UNet for 5 and 20 epochs.
- Note: providing a gif is optional and can be done as a bells and whistles below.
epoch 5

epoch 20

Deliverable 3 Add Class Conditioning to UNet
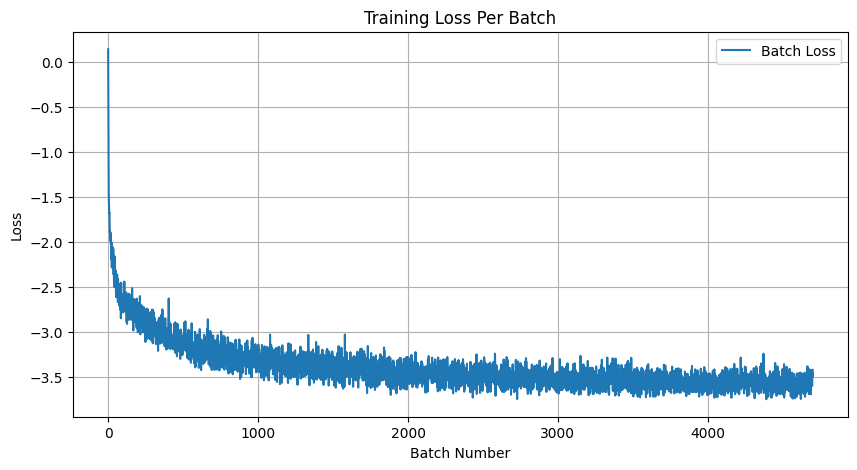
- A training loss curve plot for the class-conditioned UNet over the whole training process.
- Sampling results for the class-conditioned UNet for 5 and 20 epochs. Generate 4 instances of each digit as shown above.
- Note: providing a gif is optional and can be done as a bells and whistles below.


Note that in this part, I found that after epoch 5, the result is already quite good, only 0 and 4 number may seem not as good as results after epoch 20.
therefore I also sample the result after epoch 3, we can see that the generation quality is improving with the training epoch.
